Deterministic and probabilistic risk modelling
Deterministic risk considers the impact of a single risk scenario, whereas probabilistic risk considers all possible scenarios, their likelihood and associated impacts.

Why disaster risk is harder to see than it looks?
When a major disaster hits, it feels unprecedented. However, many other events could have caused even more damages, in some cases severe ones, but they have not even happened yet. This is where the challenges begin for decision makers. It raises a simple but difficult question: how do you plan for disasters that have not event happened yet?
If we focus only on the past, we risk developing a false sense of safety. Today’s world is highly connected, meaning future disasters will look very different from historical ones. Cascading impacts, system failures, and cross-border effects can amplify risk in ways we have not previously experienced.
To prepare effectively, experts use two different tools to measure risk: deterministic and probabilistic risk assessment.
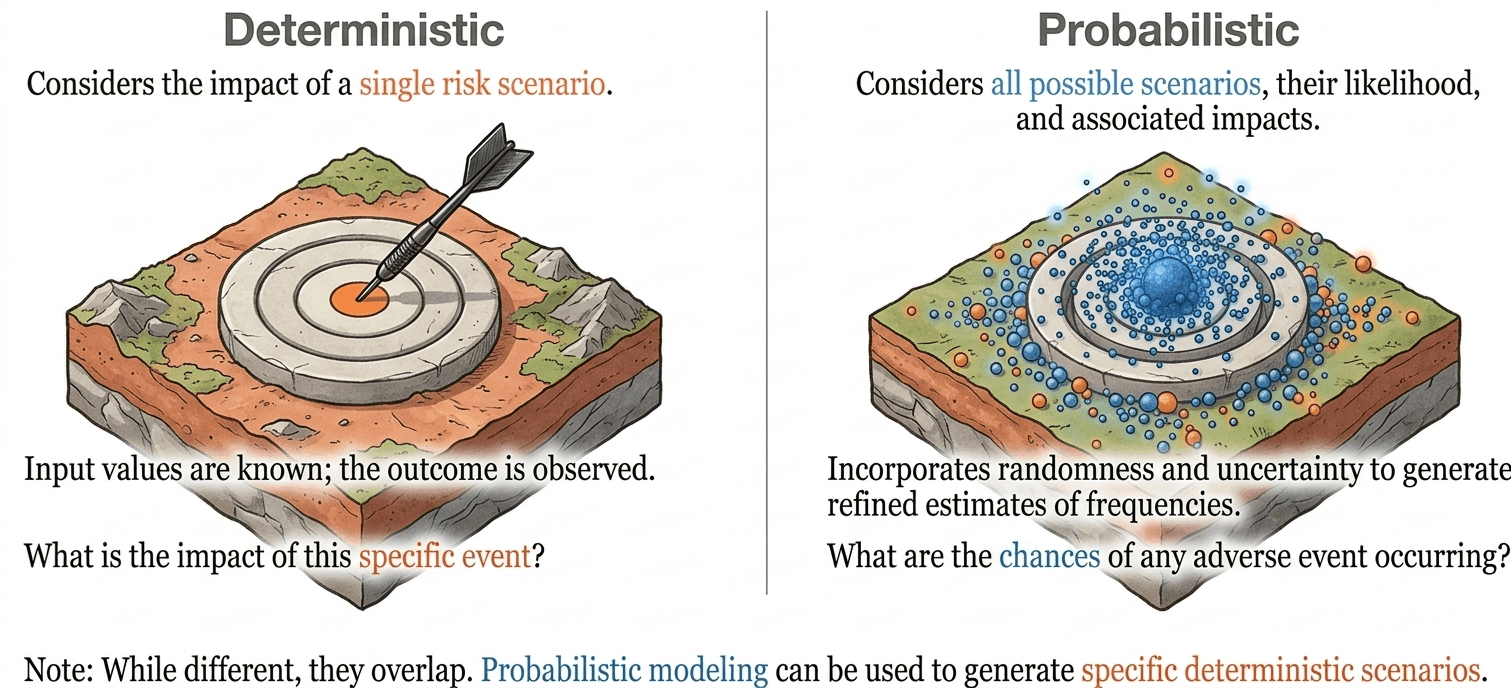
What is the difference between deterministic and probabilistic risk?
If past disasters alone cannot fully describe future risk, the next question is how risk should be analysed in practice. Disaster risk assessments generally approach this challenge in two complementary ways: by examining the consequences of specific events, and by exploring the full range of events that could occur over time.
What is deterministic risk assessment?
Deterministic risk assessment focuses on the impacts of a single, clearly defined hazard. It asks what would happen if a particular event were to occur, such as a flood similar to one experienced in the past, a severe but plausible earthquake, or a hazard associated with a chosen return period. By fixing the characteristics of the event, deterministic analysis provides a detailed picture of potential consequences, making it especially useful for testing emergency plans, evaluating infrastructure performance, or assessing the effectiveness of specific risk reduction measures.
However, disasters rarely unfold according to a single, expected scenario. Analysing a single event does not indicate how likely it is to occur, nor what its potential impact could be.
Seismic risk assessment of schools in the Dominican Republic
Latin America and the Caribbean is the second-most disaster prone region in the world, after Asia and the Pacific. To strengthen preparedness, the United Nations Educational, Scientific and Cultural Organization (UNESCO), as part of a disaster risk reduction project launched in 2020, trained local students of engineering and architecture in the Dominican Republic on how to assess the earthquake vulnerability of schools and correct the problem through retrofitting and other measures.
The first step was to identify and rectify vulnerabilities in existing schools structures, such as a fissure along a bearing wall or a lack of early warning systems. The inspectors identified risks and retrofitting opportunities at 85 schools across five municipalities in the Dominican Republic. They conveyed these findings to the local and national governments so that they could allocate targeted resources to fortify those constructions in need of retrofitting.
What is a probabilistic risk assessment?
Probabilistic risk assessment addresses this limitation. Rather than analysing one scenario in isolation, probabilistic approaches examine thousands of scientifically plausible disaster events and estimate how frequently different levels of loss may be expected over time.
By doing so, they provide insight not only into potential consequences, but also into their likelihood and associated uncertainty. This allows decision-makers to understand risk as a spectrum of possible futures, ranging from frequent low-impact events to infrequent but potentially catastrophic losses.
In this way, risk is not seen as a single outcome, but as a distribution of possible outcomes.
Climater risk and adaptation for transport networks in East Africa
Flooding already poses a significant threat across East Africa. One of the areas particularly impacted by these impacts is the transport sector. There is a pressing need to invest in resilience building, but given the scale of the challenge, identifying where and how to prioritise these interventions is key.
With this in mind, an assessment of transportation networks in Kenya, Tanzania, Uganda and Zambia identified existing vulnerabilities and modelled future disaster impacts on supply changes and trade flows. The analysis also explored several adaptation options for strengthening the resilience of road and rail links to flooding.
How the two approaches work together
In practice, these two approaches are complementary. Deterministic analyses help decision-makers understand the consequences of specific events, while probabilistic assessments place those events in context by showing how likely they are and how they compare to other possible outcomes.
Together, they provide a more complete and realistic foundation for disaster risk management in an increasingly uncertain world.
Deterministic analysis is valuable for designing and evaluating specific measures. It is particularly valuable when the objective is to understand in depth how and why a specific disaster unfolded, and the interaction between hazard intensity, exposure, infrastructure design, governance decisions, and cascading effects in a concrete and detailed way. This is precisely what a forensic investigation does by analyzing what happened, why losses escalated, where systems failed, and where resilience measures made a difference.
Probabilistic analysis is essential for understanding long-term risk, fiscal exposure, and the full distribution of possible losses, especially in a world where climate change and socio-economic development are reshaping hazard patterns.
If the goal is to understand the consequences of a specific event, for example how a hospital would perform during a major earthquake, a deterministic assessment is often appropriate. It allows planners to test a defined scenario in detail and evaluate how systems would respond. In this sense, deterministic analysis functions like a stress test: it asks whether a system can cope with a particular shock.

However, real-world risk does not come in a single, neatly defined scenario. Disasters vary in intensity, frequency, and location. This is where probabilistic risk assessment plays a critical role. By analysing a wide spectrum of possible events and estimating their likelihood, probabilistic approaches help decision-makers understand not only what could happen, but how often different levels of loss might occur. It can be used to generate multiple deterministic scenarios.
Some typical scenarios might include:
- Worst-case e.g. the maximum losses
- Best-case e.g. the losses that can be absorbed
- Most "likely" e.g. the losses that are most likely to occur
There are a several issues with a deterministic approach, including the fact that it does not consider the full range of possible outcomes, and does not quantify the likelihood of each of these outcomes. Focusing on one “worst-case” or “most likely” event can create a misleading sense of certainty. A worst-case scenario may be so extreme that it seems unrealistic, while a “most likely” scenario may understate the possibility of rare but catastrophic losses. Without understanding how probable each scenario is, it becomes difficult to judge how much attention or investment it deserves.
Return periods: understanding probability
One of the most common sources of confusion in disaster risk comes from expressions such as “a 1-in-100-year flood” or “a 1-in-200-year earthquake.” These phrases are widely used in disaster risk reduction, yet they are often misunderstood in ways that can seriously distort how people perceive risk.
A 1-in-100 flood does not mean once every 100 years or that they are safe for 99 years. It means a flood with a 1% chance of being exceeded in any given year. Instead, it is a way of describing chance, not timing. Specifically, a 1-in-100-year event has a 1% probability of being exceeded in any given year. That same flood can happen this year, next year, or several times in a lifetime.
This distinction is subtle but crucial. Probability does not work like a calendar. Each year is a new roll of the dice. The fact that it happened recently does not reduce the chance of it happening again soon.

A 1-in-100 flood does NOT mean once a century. It means a flood with a 1% chance of being exceeded in any given year. That same flood can happen this year, next year, or several times in a lifetime.
Return periods are best understood not as predictions of when disasters will occur, but as tools for comparing levels of risk. As the intensity of a hazard increases, the likelihood of it occurring typically decreases, but the potential damage increases.
In other words, small events tend to happen more often, while very severe events are rarer. A flood that causes moderate damage may occur relatively frequently. A flood that causes catastrophic damage may be far less common, but its consequences are far greater.
This is why a 1-in-200-year event represents a more extreme level of loss than a 1-in-50-year event. The 1-in-200-year event has a lower annual probability: 0.5% instead of 2% but if it occurs, the expected impact is significantly larger. The difference lies not in timing, but in likelihood and magnitude.
Risk assessment therefore considers both dimensions together: how often an event might occur and how severe its consequences would be. It is the combination of probability and impact that determines overall risk.
Probability as the standard for risk assessment
Assessing risk probabilistically remains a challenge, particularly because of the number of factors to account for and because risk is not static and is increasingly influenced by a number of other drivers, including climate change. But probabilistic risk assessments are increasingly becoming the standard for disaster risk assessment because they are the more comprehensive approach. These assessments provide us with a means of quantifying the impact and likelihood of events, while also accounting for the associated uncertainty.
What is uncertainty?
Few findings from natural and social science are 100% certain, owing to the natural randomness of hazards and the fact that information and understanding of processes is incomplete. In spite of this, we still have to make decisions for building resilience.
A risk model can produce a very precise result—it may show, for example, that a 1-in-100-year flood will affect 388,123 people—but in reality the accuracy of the model and input data may provide only an order of magnitude estimate. Similarly, sharply delineated flood zones on a hazard map do not adequately reflect the uncertainty associated with the estimate and could lead to decisions such as locating critical facilities just outside the flood line, where the actual risk is the same as if the facility was located inside the flood zone.
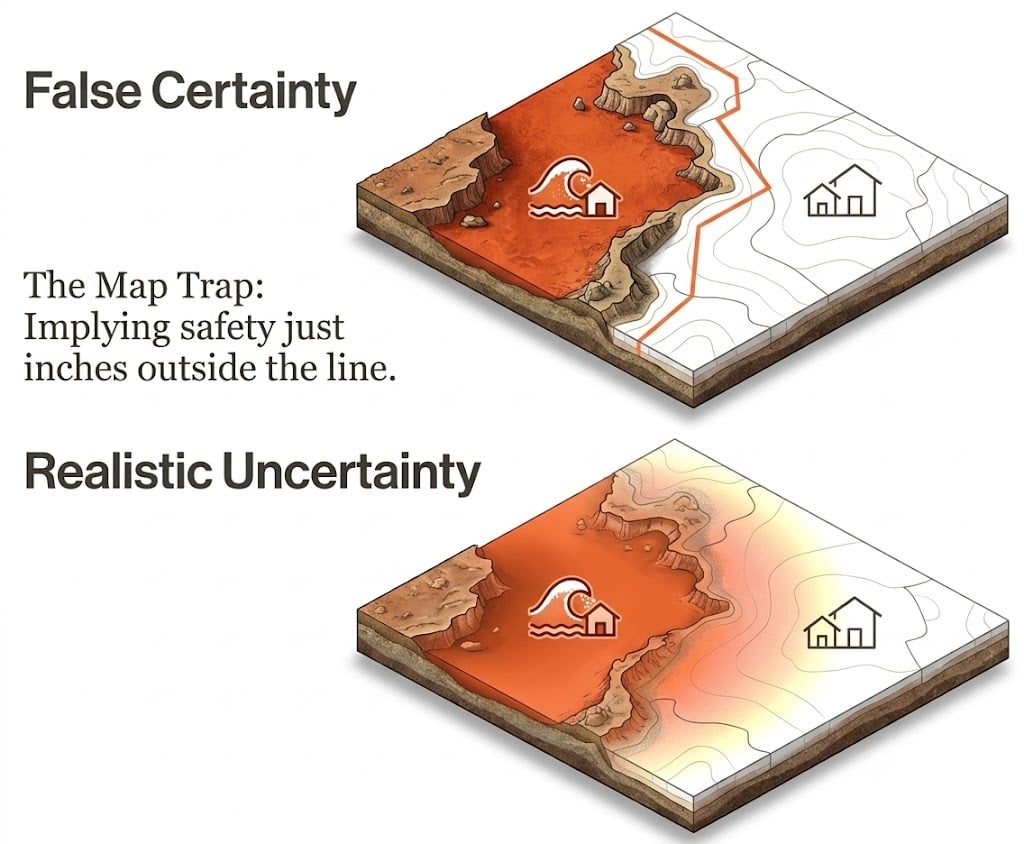
We should not be apprehensive of using information that is uncertain so long as any decisions and actions based upon the information are made with a full understanding of the associated uncertainty and its implications. It should be remembered that uncertainty will usually promote an analytical debate that should lead to robust decisions, which is a positive manifestation of uncertainty. Credible scientific information will also have any associated uncertainty clearly presented.
We cannot wholly rely on our knowledge of past events to anticipate future risk, because some disasters that could happen have not yet happened.

How do we model deterministic and probabilistic risk?
We model risk both deterministically and probabilistically using a series of components (sometimes called modules) for hazard, exposure, vulnerability and loss (or impact). In deterministic models, the output of the model is fully determined by the parameter values and the initial values, whereas probabilistic (or stochastic) models incorporate randomness in their approach. Consequently, the same set of parameter values and initial conditions will lead to a group of different outputs. We can also use probabilistic risk models to do a deterministic analysis by entering the parameters of the specific hazard event.
Hazard catalogues and event sets can be used with risk models in a deterministic or probabilistic manner. Deterministic risk models are used to assess the impact of specific events on exposure. Typical scenarios for a deterministic analysis include renditions of past historical events, worst-case scenarios, or possible events at different return periods.
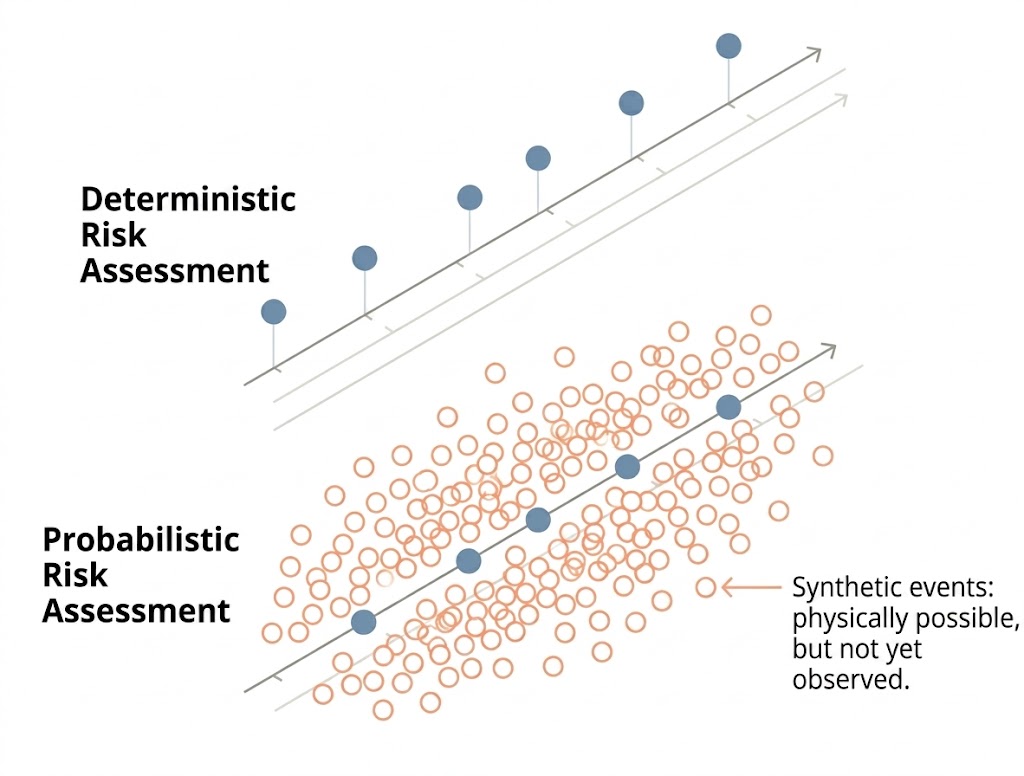
For example, a deterministic risk (or impact) analysis will provide a robust estimation of the potential building damage, mortality/morbidity, and economic loss from a single hazard scenario. Risk models are used in a probabilistic sense when an event set contains a sufficient number of events for the estimate of the risk to converge at the longest return period, or the smallest probability, of interest.
A probabilistic approach minimizes these limitations. It uses historical events, expert knowledge, and theory to simulate events that can physically occur but are not represented in the historical record. A probabilistic approach can generate a catalogue of all possible events, the probability of occurrence of each event, and their associated losses.
As such, they provide a more complete picture of the full spectrum of future risks than is possible with historical data. While the scientific data and knowledge used is still incomplete, provided that their inherent uncertainty is recognized, these models can provide guidance on the likely “order of magnitude” of risks.

Risk metrics: the key for resilience
The results of probabilistic risk models are normally presented in terms of standard measures (metrics) such as average annual loss (AAL). AAL is the expected average loss per year considering all the events that could occur over a long time frame. It is a compact metric with a low sensitivity to uncertainty. Unlike historical estimates, AAL takes into account all the disasters that could occur in the future, including very intensive losses over long return periods, and thus overcomes the limitations associated with estimates derived from historical disaster loss data. Most probabilistic risk assessments have been developed commercially for the insurance industry and cover specific risks, mainly in higher-income countries. However, they are rarely accessible and are based on proprietary models. While more and more public-domain risk models are now being developed, the use of different methodologies and data sets makes comparison difficult.
A second output is the probable maximum loss (PML) for different return periods. PMLs can be expressed as the probability of a given loss amount being exceeded over different periods of time. Thus, even in the case of a thousand-year return period, there is still a 5% probability of a PML being exceeded over a 50-year time frame. This metric is relevant, for example, to the planners and designers of infrastructure projects, where investments may be made for an expected lifespan of 50 years.
In the development of risk models, many different data sets are used as input components. The level of uncertainty is directly linked to the quality of the input data. In addition, there is also random uncertainty that cannot be reduced. On many occasions during model development, expert judgment and proxies are used in the absence of historical data, and the results are very sensitive to most of these assumptions and variations in input data. As such, outputs of these models should be considered indicators of the order of magnitude of the risks, not as exact values. Better data quality and advances in science and modelling methodologies reduce the level of uncertainty, but it is crucial to interpret the results of any risk assessment against the backdrop of unavoidable uncertainty.
Last updated: April 2026